Unpacking the Infrastructure Behind Large Model Training
I recently stumbled upon Imbue's post detailing how they setup their infrastructure to train their 70 billion parameter model. I found it fascinating and there was a bunch I didn't understand. So, here's me trying to make-sense of it all!
Fat-Trees
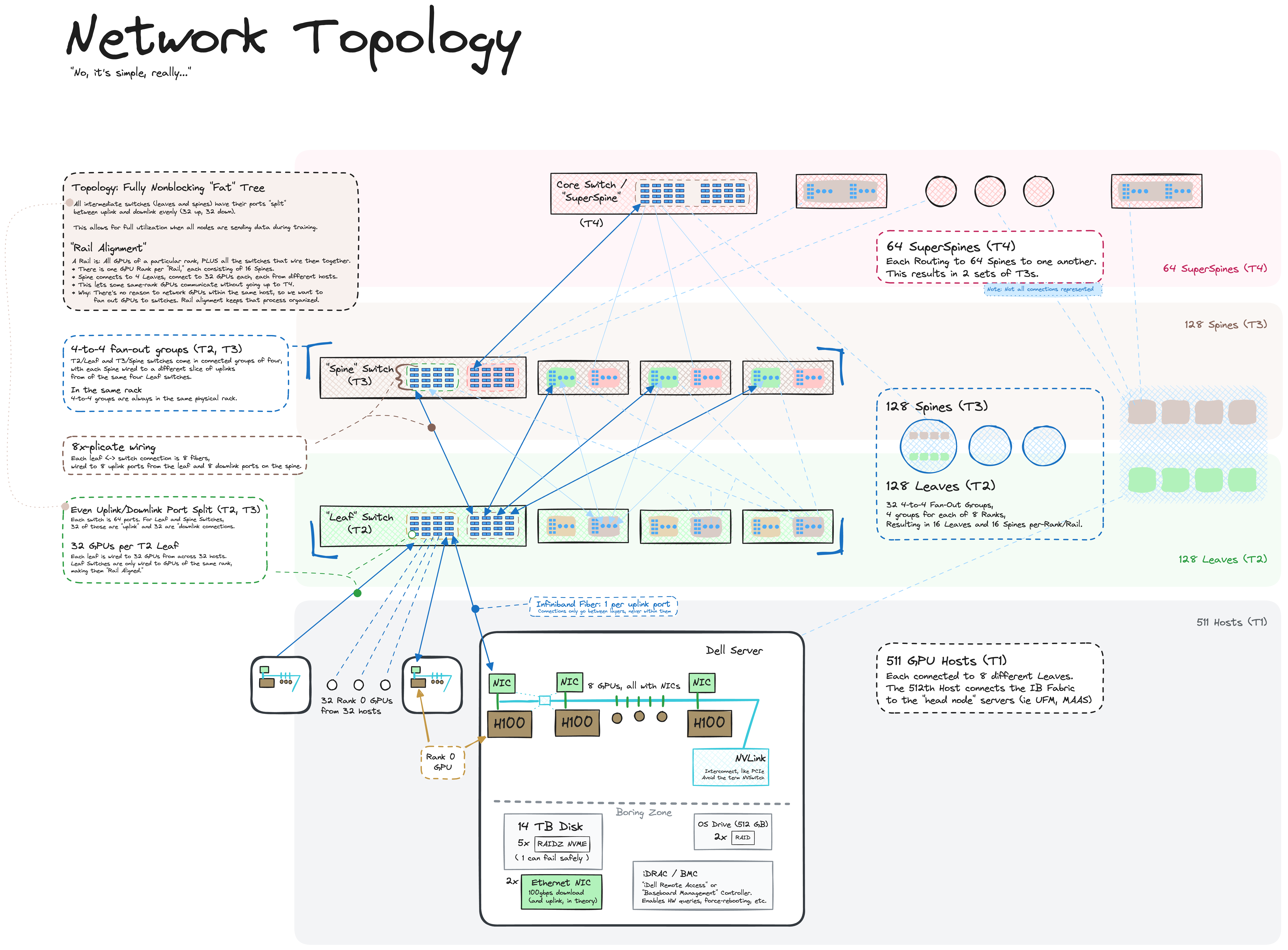
According to Imbue's network topology, they utilize a fat tree network -- a network design where the branches are thicker towards the top of the tree. The branches represent links connecting a node to its parent. So a thicker branch means more connected wires, meaning increased communication bandwidth.1.
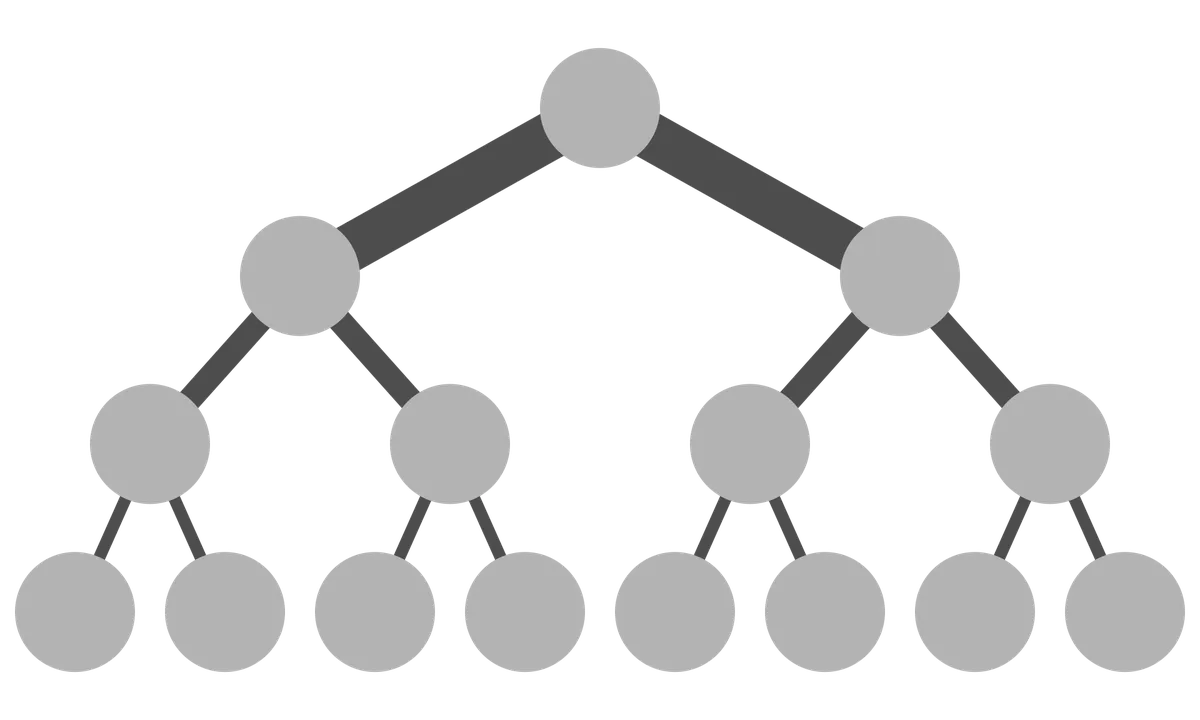
In other words, a fat tree describes how the servers and switches are hooked up together in a data-center and the number of wires/connections between the hardware increases the further up the tree you go, thereby increasing bandwidth the closer you get to the top.
The servers in this setup are located at the leaves of the tree and the switches are the internal nodes 1 (commonly referred to as spline switches2).
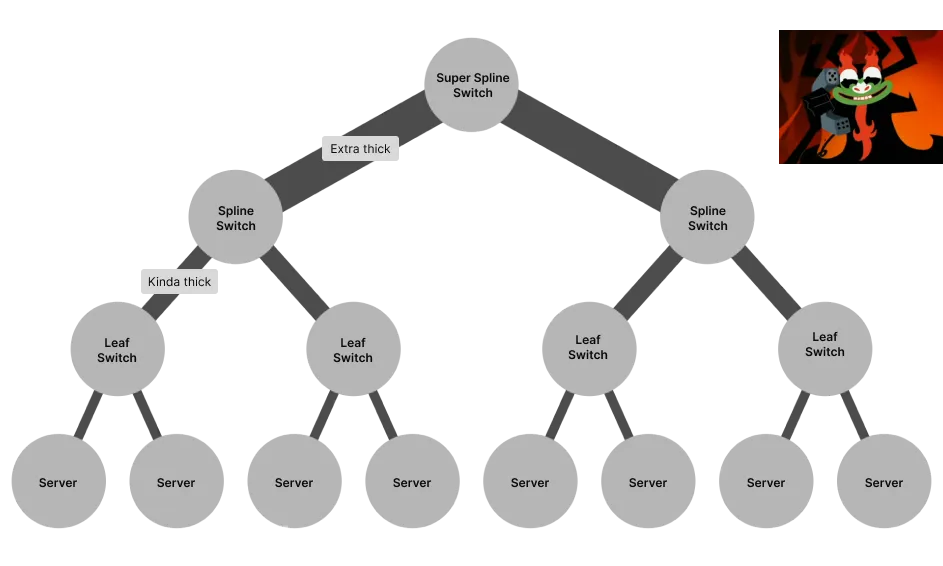
This isn't particularly special to Imbue or any company, this is just NVIDIA's recommended network topology 3. And could potentially be how a data-center vendor claims your cluster is setup.
Of course, the optimal network topology comes down to use-case. My interpretation is that fat-tree hits the sweet spot regarding cost, high-bandwidth, low-latency, power consumption, and scalability 4. Also, it seems pretty simple to understand (compared to other designs), making it a popular design choice 5.
Some alternatives to fat-tree include Multi-tiered networks, Flattened Butterfly, Camcube, and BCube 4.
The fat-tree diagram above is a little misleading though. It's suggesting that the leaf nodes are servers, but in Imbue's case, the leaf nodes are GPU's. Each GPU in each server has its own Network Interface Card (NIC) that connects directly to a leaf switch. For a given server, each of its GPU's are connected to a different leaf switch.
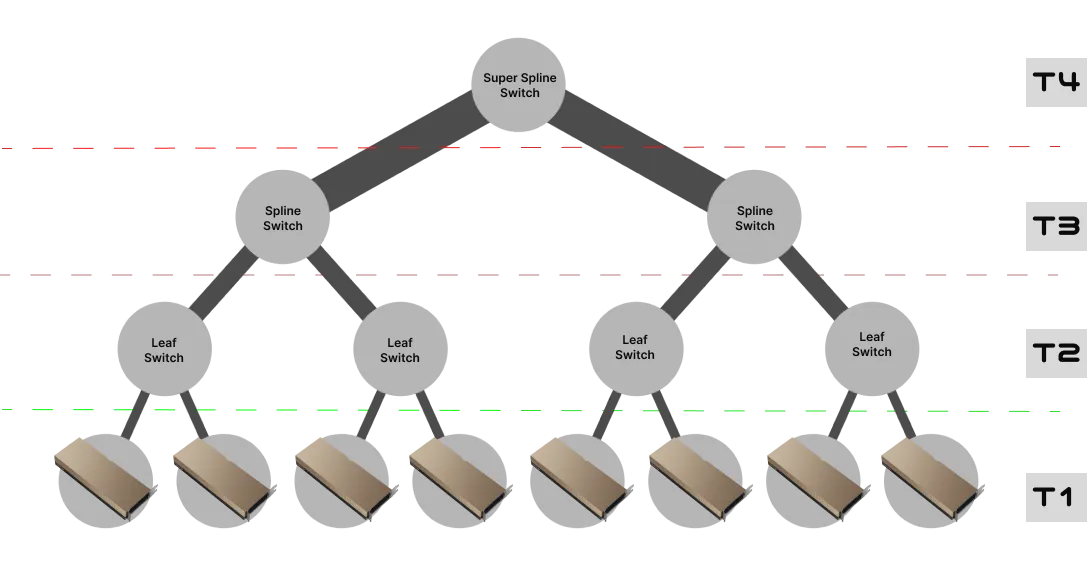
This diagram still isn't quite accurate. At T4, there are actually 64 super spline switches, not just a single root switch. At T2 and T3 there are 128 switches each, resulting in alot more connectivity between the leaf switches and the parent spline switches3. So, this depiction is a bit sparse, but it still conveys the hardware-hierarchy.
InfiniBand
Imbue's cluster has 4,088 NVIDIA H100 GPU's in it. These GPU's are hooked up to ConnectX-7 network cards which utilize InfiniBand Architecture (IBA) - a networking system comprised of hardware, adapters, protocols, and drivers. IBA is basically an alternative to ethernet that is quite suitable for high-performance computing. This setup provides pretty remarkable network performance with a throughput ceiling of 400Gb/s6.
Whoa whoa whoa, how does IBA achieve such performance?
That's the cool part, IBA off-loads much of the IO operations from the CPU to its own hardware through a process called Remote Direct Memory Access (RDMA)7, allowing for multiple concurrent communication connections without CPU overhead (such is the case for traditional protocols). An endpoint (or server) can communicate through multiple IBA ports and paths through the fabric, resulting in higher bandwidth and fault tolerance 8. So, in our case, a GPU can communicate directly with another GPU (via the ConnectX-7 cards and IBA fabric) without involving the CPU. Going further, a GPU in server A could, in theory, communicate directly with a GPU in server X at 400Gb/s!
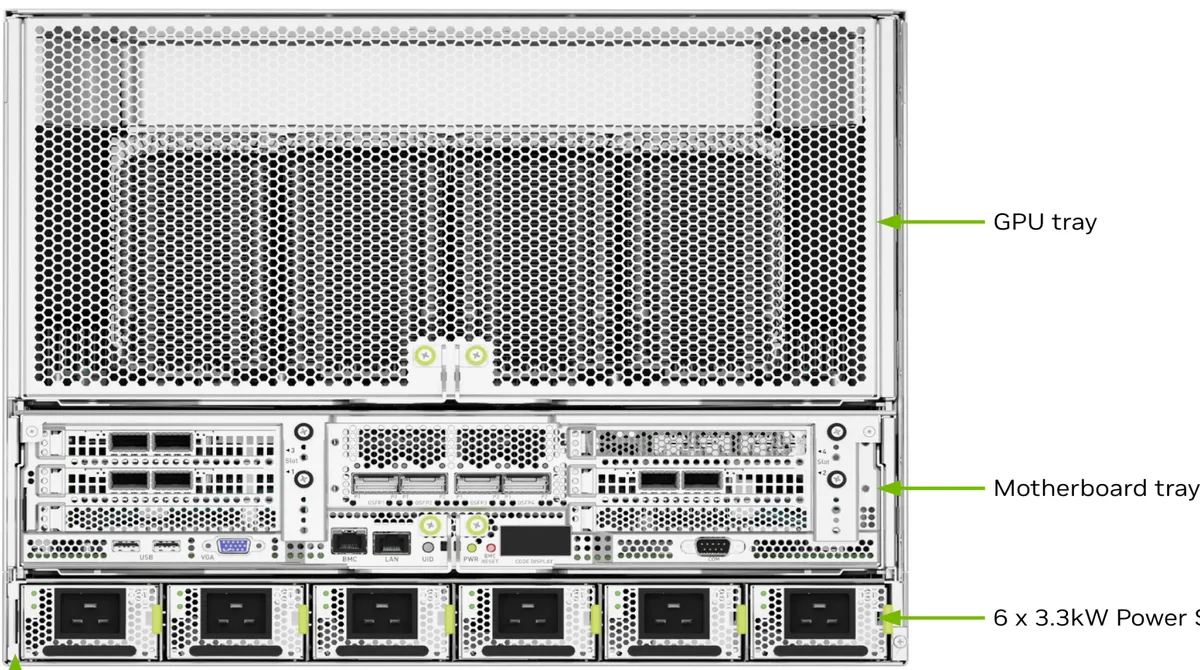
Let's check out how the GPU's are connected to these IBA ConnectX-7 cards, bringing our attention to the back of an H100x8 rack box.
Check out the 4 OSFP ports on the back of the motherboard tray, right in the middle. These would be connected directly to a leaf switch (remember the fat-tree above?).
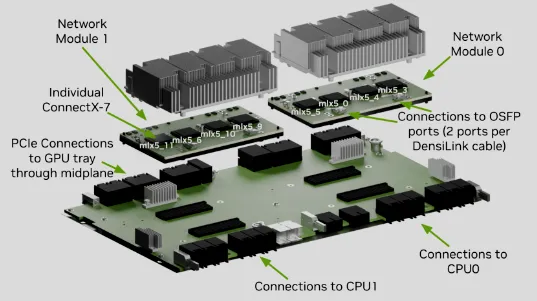
If we look at the guts of the motherboard tray, we can follow the 4 OSFP ports via their DensiLink cables straight to ConnectX-7 cards. These cards are sitting on an interposer board. The GPU's communicate with these ConnectX-7 cards through the network interposer board.
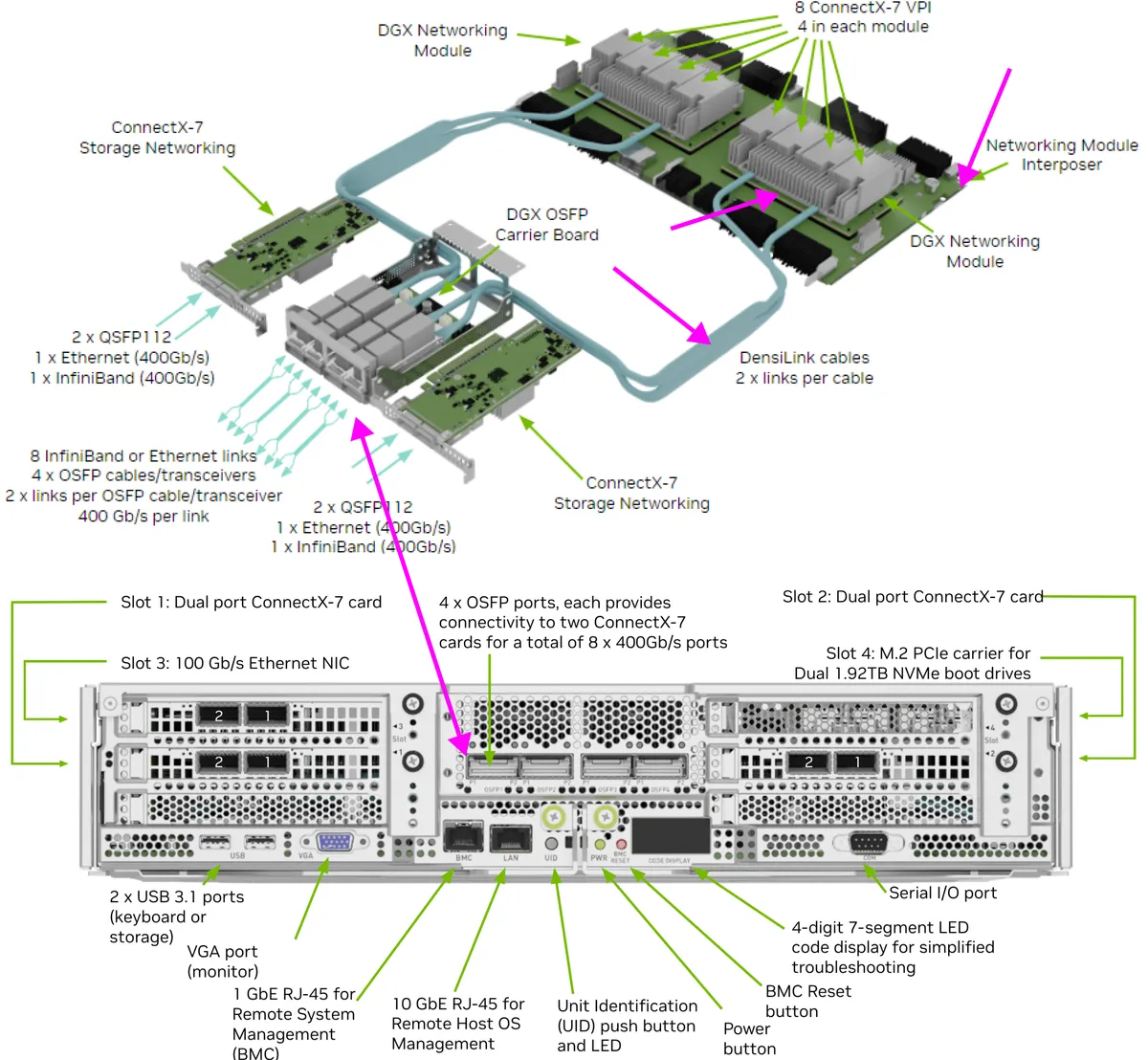
Also, here's a more detailed look at the ConnectX-7 cards, making the DensiLink -> ConnectX-7 -> GPU PCIe Connection a little more obvious.
So what?
Aside from this stuff being cool, maybe one day you will be lucky enough to setup large model training infrastructure from bare-metal, and on that day, the data-center vendor will explain the network's design. It will be up to you to verify their claims.
There is a non-zero chance that you may have to troubleshoot something lower level if a training run fails. Perhaps a DensiLink cable isn't fully connected to a ConnectX-7 card and one GPU is being underutilized. Hopefully, after reading this, you can somewhat speak the language when you get on the phone with the vendor.
Ending notes
This post mainly focused on the fat-tree design, InfiniBand, and hardware connections, skipping over concepts like Rail optimized design and GPU rank. Perhaps they will make it into another post.
Anyway, thanks for reading! Keep the bits warm!
(H100 Rack Box images pulled from NVIDIA).
{kind=link}